Longnight Blog
使用Telegram Bot来实现推送通知
2018-12-12 00:00运营UGC时通常都需要某种消息推送服务,当服务器发生关键性事件时,能够即时通知。过去我常使用的email推送,最近发现好像telegram推送也很强大好玩,现在分享一下如何实现。
1, Telegram方面的设置, 首先你得有个telegram账号并安装好桌面端.
1.1 整一个telegram bot, 可以通过点击这里来创建:TelegramBotFather, 在与它的对话框中输入 /start /newbot 等指令,按照提示一步步,到最后获得一个新bot,以及一串形如以下的token:
987654321:FEDCBA_dfoiuweSWEczgxT7-l4r9Y
这串东西不应泄露给他人,否则被人滥用的话会导致该bot被禁止.
1.2 找到你的telegram chat_id:
1.2.1 用客户端往bot发言, 内容是什么不重要
1.2.2 将前面获得的token替换掉这个url中的XYZ部分,
https://api.telegram.org/botXYZ/getUpdates
它实际上应该看上去应该是这样的:
https://api.telegram.org/bot987654321:FEDCBA_dfoiuweSWEczgxT7-l4r9Y/getUpdates
然后访问这个url, 在返回的json中你很容易可以找到id这个键(与username,first_name)相近. 那串数字(139000174)就是要找的id
1.2.3 好了, 有了token和 chat_id 就可以从bot往自己发消息了, 试一试:
curl -k --data chat_id="139000174" --data "text=Have a good journey, Mr. Weyland." "https://api.telegram.org/bot987654321:FEDCBA_dfoiuweSWEczgxT7-l4r9Y/sendMessage"
此时客户端应立即收到来自David的消息: “Have a good journey, Mr. Weyland.” 哈哈哈.
2, 实现推送的脚本代码 好了, 基本所需变量已经准备就绪, 测试也通了, 接下来需要好用的脚本使得跑起来更顺手. github上有很多不同语言实现的telegram bot, 这里我选用了pyTelegramBotAPI
2.1 安装 pip install pyTelegramBotAPI
2.2 使用.这里我们因为是给自己推消息,所以可以略去他家 readme 中的大部分内容,直奔api而去:
import telebot
bot = telebot.TeleBot("YOUR TOKEN")
bot.send_message("YOUR CHAT_ID", text)
就是这么简单了! 最后,应参考telegram bot 的官方 api, 看看是否用得上多媒体/图片/声音/HTML/markdown 等参数, 按照自己实际需求定义个函数包裹一下. 需要提醒的是, 如果发送html格式的话, 能用的tag有限, 而且不能嵌套tag, 还是参考api 文档吧! 事情就是这么简单,且又好使. 微信那边要实现类似功能,得用公司资质申请个啥服务号, 每年300元, 不便宜又有风险. Telegram 结合channels,group,bot,构成了一个极其多样化并且提供强大能力的平台,除开被墙这个因素,很值得自媒体从业人员和开发者投入精力。
SSR(Server side render)和SPA(Single Page App)以外的另一种架构实践
2017-03-25 00:00待填入内容.
从以前的老博客:maruba.be/1984 迁移过来
2016-09-03 00:00由于博客平台 maruba.be 宣布将停止运营,所以我在github使用Jekyll建了这些静态页,将过去写在那边的一些技术文章保存到这边。
使用UID,和一个可以逆推的生成UID方法
2015-11-11 00:00在某些场合,暴露数据库的记录ID,譬如这样的: http://domain.me/user/7878 ,
可能会带来危险,因此我们应该使用UID之类的东西来代替它。
最简单的做法是:
随机生成无规律、url安全的字符串作为UID, 然后保存在数据库里;
需要时通过这个UID查询到相应的数据库记录。
但是保存UID在数据库里,可以说是向数据库添加并使用不必要的东西来查询,因此是违反了数据库设计范式的。
同时也因为增加查询而影响性能。
更好的方案是,寻找一个可靠的算法,它应当能够:
- 生成看上去无规则的随机字符;
- 可以指定生成UID的格式,长度;
- 可以逆推,即反向解出来。
这篇博客 http://blog.cryptographyengineering.com/2011/11/format-preserving-encryption-or-how-to.html介绍了一种名为 Format Preserving Encryption 的算法,感觉正好满足以上需求。一个典型的应用场景是:一种商业机器只接受信用卡号码即16位数字格式的输入,而你希望在传输时加密真实的信用卡号码,到达后再还原出来,这种FPE算法就解决了这个问题。

这个加密算法在python的实现叫libffx,为了方便使用,我对它包裹封装为如下代码,应用了在自己经手的网站生产环境中,减少触碰数据库,对网站速度有帮助。 是否应该这样使用UID,取决于自己网站性能瓶颈是出现在CPU,还是数据库。 注:这种算法 不可用于敏感数据,如用户密码的加密。
下载安装好:
python-dev, python2-dev, or python3.4-dev 之一;
libmpc-dev;
gmpy: https://github.com/aleaxit/gmpy;
libffx: https://github.com/kpdyer/libffx (手动安装 python setup.py install );
import ffx
K = 'can_any_strings' # AES key must be either 16, 24, or 32 bytes long
def ffx_encrypt(id, blocksize=8):
"""FPE encrypt.
:id Intege: ID to be encrypted
:blocksize Intege: the result UID length
"""
ffxObj = ffx.new(K, radix=10)
D = ffx.FFXInteger(id, radix=10, blocksize=blocksize)
return ffxObj.encrypt(K, D).to_str()
def ffx_decrypt(uid):
"""FPE decrypt.
:uid string: UID to be decrypted
"""
ffxObj = ffx.new(K, radix=10)
D = ffx.FFXInteger(uid, radix=10, blocksize=len(uid))
return ffxObj.decrypt(K, D).to_int()
运行例子:
>>> ffx_encrypt(1002, blocksize=8)
'24819966'
>>> ffx_decrypt('24819966')
1002
使用Tornado实现网易评论的递归嵌套盖楼效果
2014-09-23 00:00为了探索Tornado的Coroutine、Future,写了这个玩意儿。
思路基本是按照以前这两篇日志的
http://maruta.be/1984/94
http://maruta.be/1984/95
原本基于Django实现,现在改为Tornado实现,
改动的地方是ORM操作的东西变成了自己写些raw sql,
Coroutine、Future这些概念一下子比较难透彻理解,
又包含了递归函数,局面变得比一般练习代码复杂不少。
因此还有改进的地方。
这个项目保存于 https://github.com/longnight/Netease_style_guestbook
共有3个方案
1,
app.py:
tornado + MySQL
2,
app_coroutine.py:
tornado + MySQL + coroutine
3,
app_motor.py:
tornado + Mongodb + coroutine
实际效果是这样的:
tornado_netease3.jpg
{kind=link}
Django cache 系统再思考
2014-09-05 00:00Django 的cache 系统提供了多个粒度的cache手段,从整站cache ,到 views cache,再到 template层上还可以局面代码cache,简直是想缓存哪里,就缓存哪里。
但问题来了:如果我们的views函数包括了复杂的计算和频繁读取,那么在template层面上的缓存能节省这方面的开支吗?
答案是不能,因为每次页面request时调用这个view函数,该计算的还得计算,即使你在模板中缓存了局部表现代码,那也只是浪费掉后台的结算结果而已。
解决办法是?
这里的这篇博客详细解释了解决思路(需要翻墙):
http://migaat.blogspot.com/2011/11/different-ways-for-low-level-caching-in.html
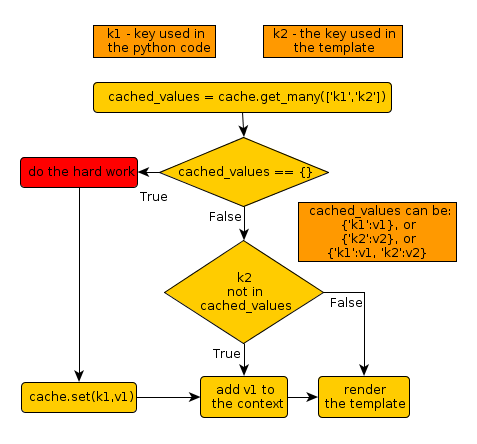
有点复杂,但核心不外乎检查缓存是否存在,如果不存在再去计算。
与我前面的实现相比,大同小异,他多了与template 缓存对照的一步,少了检查计算结果为空集的一步。
在俚语维基的实践表明:
1,页面载入时间大部分消耗于计算相似词条、投票统计等上面,开启缓存节省掉这俩的计算之后,所有页面载入速度提升了几倍,部分内容复杂的词条提升了近10倍;
2,每个页面即使执行数据库100-300次queries,速度仍然非常快,与后台的计算相比,这块不是导致打开网页缓慢的第一因素,
但使用恰当的缓存方案之后,数据库查询骤降至20多次,进一步榨取载入速度——从300-600毫秒减少到30毫秒。
以上数据是本地破电脑跑的,由 django-debug-toolbar 提供。到了服务器上差距不至于有这么大。
PS:
通常提到cache都是基于指定时间来让它过期的,后来仔细想了下,其实可以按照存取频率来决定过期。
比如某个视图函数,当被访问100次之后,就更新cache。
这个不难实现,将原本要读写的缓存键值对加入计数器,然后判断,若>100 即执行删除、再计算即可。
stackoverflow 上就有人提到过相似的需求,当有访客发表评论时,执行更新缓存:
http://stackoverflow.com/questions/2268417/expire-a-view-cache-in-django
利用cache在多个网站实例中共享数据
2014-09-05 00:00前文提到liyuwiki使用了一个全局变量来储存访客搜索过的关键词,
由于网站是在nginx后跑起多个实例的,
那么就必须让这个对象被共享,大家都可以读取、修改。
解决办法就是利用cache,
在django中,一旦在settings里定义好cache的后台之后,其他的用法都是一样的,可移植,
跟orm一样可以随意写,非常方便。
操作cache的伪代码如下:
the_cache = get_cache('default')
if the_cache.get('my_key'): # 如果该缓存已存在:
if the_cache.get('my_key') == 'non_exist': # 检查该缓存是否为某个指定标记
my_value = []
else:
my_value = the_cache.get('my_key')
else: # 该key尚未被计算过,开始:
generate my_value code block... # 开始处理。这些计算仅发生在第一次;保存到cache后便不再发生
if my_value: # 将计算结果写入cache
the_cache.set('my_key', my_value, 60*20)
else: # 如果计算结果为空集,则往cache写入一个值
the_cache.set('my_key, 'non_exist', 60*20)
django文档里说“so-so traffic”的小型站点没必要使用cache,但是liyuwiki每个页面上都有些过于昂贵的计算开销,比如寻找相关词条,这种计算要么固化到数据库要么缓存,否则每次都运算一回那也太浪费,有必要优化一下。果然保存到cache里之后, 速度快了很多。
应用:python的deque
2014-09-01 00:00网站有一个需求,需要这么一个全局的(容器)对象,可迭代内部的item,可限制数量,当在1端加入新item时,末端相应地就自动删除1个。 利用这个容器,可以将最近用户搜索过的关键词展示出来,展示最近10个,作为全局变量随时使用,更新,不固化到文件或数据库里。
python 自带了一个这样的东西:deque (音 deck)
from collections import deque
a_deque = deque([], 10) # 生成一个空的deque,限制为10个元素
当发生了搜索行为时:
a_deque.appendleft(keyword)
如果该关键词已存在于这个deque:
a_deque.remove(keyword)
python 的list也能实现相似的操作,但使用deque更高效,无论从哪一端增加元素,时间复杂度都是O(1),删除指定元素也是O(1),并可以指定最大长度。 有了deque,就不用自己去实现这个“一端进、一端出”的队列对象。
liyuwiki.com 上的效果:

ps,推荐书籍: 《Problem Solving with Algorithms and Data Structures》这本书很详细地解释了python中几个数据结构的例子,实现代码。其中就包括了deque。另外还有stack, queue, unordered list, ordered list等,对理解数据结构很有帮助(但此书中的deque是教学案例,与python真正的deque也就是我前面应用的略有差异)。全书使用python 3作为唯一教学语言,跟传统的用C、C++解释数据结构的书相比,此书完全不涉及硬件或内存,依我看,就是更加抽象。行文也较为细致详尽,完全面向新人。不管怎么样,从python的角度来教授数据结构、算法,在市面上凤毛麟角,打算深入python的程序员们,不必要再学其他语言了,就这本已很好。免费。篇幅不大,pdf 236页A4。 http://interactivepython.org/runestone/static/pythonds/index.html
记录下现实中遇到的陈列商品问题的解决思路
2014-08-27 00:00设有n个商品需要一并展示在网站首页,每行3个,n的值是变动的。不分页。
那么情形大致如下图:

面临的问题是:当n不是3的倍数时,末行总会出现空档,即问号所示,有时为1个,有时为2个.
怎么解决?
有2个办法:
1,在末行补上广告图片placeholder:
if n % 3 != 0:
codes to show first placeholder img...
if n % 3 == 1:
codes to show second placeholder img...
2,删除多出的一两个商品,不予展示。用函数来表达,就是已知有n个商品,求n下最大的3的倍数m,展示m个商品。
def multiple_3(n):
while n > 2 and n % 3 != 0:
n -= 1
return n
以上应可以用lambda一行到位,这里只是记录一下思路。
template Philosophy, Django vs Tornado
2014-08-26 00:00最近因为工作需要,接触了Tornado的模板,感受到了与Django的不同, tornado的模板几乎可以将任何python语句塞进去,比如:
判断:
{% if variable %}
blabla...
{% else %}
blabla...
{% end %}
迭代:
{% for item in somethings %}
blabla
{% end %}
赋值:
{% set somelist = range(1,10) %}
列表推导:
{% set a = [x for x in v if x % 2 == 0] %}
lambda:
{% set x = filter(lambda ...blabla ) %}
……
根据tornado的官网文档,还有更多复杂用法,但!当你手中握着锤子时,全世界看上去都像是钉子了,tornado这种自由感让人不知不觉间忘记了逻辑与表现须尽可能分离的祖训,前端同事看到的是到处散落着python语句和变量的html。
再回过头看django 模板的理念:“the template system is meant to express presentation, not program logic….. and the template system will not execute arbitrary Python expressions.”django 不让自己的模板系统发育成另一门语言,觉得这种坚守相当高瞻远瞩。
Django实践:获取随机图片地址的自定义templat tag
2014-07-27 00:00这个自定义的tag应用在 liyuwiki.com,当用户搜索返回没有结果的页面时,该tag会在指定目录下随机获取一个图片文件地址。 比如:http://liyuwiki.com/search/?q=non-exist 这个搜索结果页面每次呈现的图片都不同。
1,在app目录下建立文件夹templatetags\,再在其中建立__init__.py、random_img.py 2,random_img.py 内容如下:
import os
import random
import posixpath
from django import template
from django.conf import settings
register = template.Library()
def is_image_file(filename):
"""Does `filename` appear to be an image file?"""
img_types = [".jpg", ".jpeg", ".png", ".gif"]
ext = os.path.splitext(filename)[1].lower()
return ext in img_types
@register.simple_tag
def random_img(path):
"""
Select a random image file from the provided directory
and return its href. `path` should be relative to MEDIA_ROOT.
Usage: <img src='{% random_image "images/whatever/" %}'>
"""
fullpath = os.path.join(settings.MEDIA_ROOT, path)
filenames = [f for f in os.listdir(fullpath) if is_image_file(f)]
pick = random.choice(filenames)
return posixpath.join(settings.MEDIA_URL, path, pick)
3,在template中导入这个tag 后即可使用:
{% load random_img %}
<img src='{% random_img "your_path" %}' />
这段代码实际出自这里,我作了非常轻微的一点小修改,避免了原作者忽略大写文件扩展名的疏忽。
不仅可以用于随机图片,也可以随意选择其他文件,css,js,mp3,html等,这样一想似乎可以产生一些有趣的点子。
补记:以上这段自定义tag写于2007年。2008出版的《Python Web Development with Django》(Jeff
Forcier,Paul Bissex,Wesley Chun) 有一个几乎完全相同的版本,可能就是借鉴前面的吧。
import os
import random
import posixpath
from django import template
from django.conf import settings
register = template.Library()
def files(path, types=[“.jpg”, “.jpeg”, “.png”, “.gif”]):
fullpath = os.path.join(settings.MEDIA_ROOT, path)
return [f for f in os.listdir(fullpath) if os.path.splitext(f)[1] in types]
@register.simple_tag
def random_image(path):
pick = random.choice(files(path))
return posixpath.join(settings.MEDIA_URL, path, pick)
这本书还提供了一个可以选择扩展名的进化版:
@register.simple_tag
def random_file(path, ext):
pick = random.choice(files(path, ["." + ext]))
return posixpath.join(settings.MEDIA_URL, path, pick)
在模板里这样用:
<img src="{% random_file "special/icons" "png" %}" />
Django实践:自定义表单验证:词条唯一性,图片体积尺寸
2014-07-17 00:00以下代码用于 liyuwiki.com ,确保了用户在提交内容时,从form层面验证:词条是否已存在、图片文件是否符合要求。
def check_exist(value):
t = Terms.objects.all()
value = unicode(value)
value = ' '.join(value.split())
if t.filter(term=value).exists():
uid = t.get(term=value).uid
error_tips = mark_safe(u'【<a href="/%s.html">%s</a>】已经存在了' % (uid, value))
raise ValidationError(error_tips)
def check_img(self):
fileExtension = os.path.splitext(self._name)[1].lower()
if fileExtension not in ['.jpg', '.jpeg', '.png', '.bmp', '.gif']:
raise forms.ValidationError(u"文件类型错误: %s" % fileExtension)
w, h = get_image_dimensions(self)
if w > 1000:
raise forms.ValidationError(u"你上传的图片宽度是 %ipx. 不能超过1000px." % w)
if h > 3000:
raise forms.ValidationError(u"你上传的图片高度是 %ipx. 不能超过3000px." % h)
以下是表单:
class TermForm(forms.Form):
term = forms.CharField(max_length=20)
docfile = forms.ImageField(required=False)
def __init__(self, *args, **kwargs):
super(TermForm, self).__init__(*args, **kwargs)
self.fields['term'].validators.append(check_exist)
self.fields['docfile'].validators.append(check_img)
def clean_docfile(self):
if self.cleaned_data['docfile']:
if self.cleaned_data['docfile'].size > 3145728:
raise forms.ValidationError(u"图片体积太大了.最多接受3MB.")
return self.cleaned_data['docfile']
需要注意的是包含了html的ValidationError信息,使用了Django的mark_safe处理,以免被模板系统转义。
Django实践:设计人类易于识别的url
2014-07-01 00:00http://liyuwiki.com/term/?q=%E7%8C%B4%E6%9C%BA
http://liyuwiki.com/929619.html
以上两条url,显然第二条更容易理解、记忆、并在各种场合中传播。相信很多人都有过这样的经历:把网址拷贝下来贴到论坛或QQ里,却被对方截短,失效了。
基于这样的想法,我认为把标题写到url里这种方案不适合中文。
那么在url中用数字如何?
见过不少网站直接在url中展示该篇文章在数据表中的primary key,妾以为甚不可取,似乎向黑客们暴露了什么。
所以我使用了这个一个方案:生成每条数据除了数据库分配给它1个pk id之外,还额外生成1个6位随机阿拉伯数字构成的uid。为什么不使用(大小写)英文字母组合?我认为普通用户会更排斥后者,字母远比数字令普通用户退避三舍。
这个生成uid的函数写起来也不复杂。但作为生产环境需要多做1步:检测生成的结果是否已存在于数据表,若是,则再来1次,直至得到这个独一无二的随机6位数。
函数:term_uid()
输入:无
输出:1个与表内已有的记录不冲突的6位数。
import random
def term_uid():
uid = random.randint(100000, 999999)
while Terms.objects.filter(uid=uid).exist():
uid = random.randint(100000, 999999)
return uid
163 网易评论的无限嵌套 代码样例 之 2
2014-06-30 00:00之前的代码已经基本实现,但是很不优雅,因为传给模版系统的是字符串而非变量,后期就无法灵活改动。
经过思考,终于找到几近完美的办法,思路就是重写递归相关的函数,做到接收1个评论id,输出一个字典,字典结构: {'<div class="commant"><div class="commant">...':[querySet1,querySet2,querySet3...]},然后,在将这样的字典加入到列表中,最后将列表传到模版系统。模版系统方面进行多次迭代取出n个<div class="comment">以及相应的querySet,然后取值,逐个补上</div>结尾。最后就是一个非常灵活的局面,div wrap 层和querySet都很好的兼顾到了。
下面附上代码和效果:
递归函数:
def mult_div_qs(qs_id, mdq_dict={}, sum=0, qs_list=[]):
c = Comments.objects.all()
head_str = '<div class="comment">'
if not c.filter(id=qs_id):
return mdq_dict
else:
qs = c.get(id=qs_id)
sum = sum + 1
qs_list.insert(0, qs)
key = str(head_str * sum)
mdq_dict = {}
mdq_dict[key] = qs_list
if not qs.quote_who:
return mdq_dict
else:
qs_id = qs.quote_who
return mult_div_qs(qs_id, mdq_dict, sum, qs_list)
view 的代码:
def index(request):
c = Comments.objects.all().order_by('-id')
addcomform = Addcomform()
qs_list = []
for i in c[:80]:
div_qs = mult_div_qs(i.id, {}, 0, [])
qs_list.append(div_qs)
context = {'c_list': c, 'addcomform': addcomform, 'qs_list': qs_list}
return render_to_response('index.html', context, context_instance=RequestContext(request))
Template那边的代码(注意要加上autoescape off):
{% for i in qs_list %}
{% for j, k in i.items %}
{% autoescape off %} {{ j }} {% endautoescape %}
{% for l in k %}
<span class="id">ID:{{ l.id }}</span>
<span class="quote_who">quote_who:{{ l.quote_who|default:"未引用" }}</span>
<span class="author">作者:{{ l.author|default:"匿名" }}</span>
<span class="created_time">发表:{{ l.created_time|date:"H:i:s" }}</span><br />
<span class="comment_text">{{ l.comment }}</span></div>
{% endfor %}
{% endfor %}
{% endfor %}
这样,通过递归思想,寥寥几十行就完成了很多程序无法做到的嵌套效果。
并且模版系统接收到的数据是完整可迭代的queryset,也就意味着随意使用了。
使用python+Django 简单实现网易评论的无限嵌套 代码样例
2014-06-28 00:00一向觉得163网易评论,是国内文章评论系统做得最优秀的,除了本身运营的自由开放态度之外,技术上的因素也很重要:它的多层嵌套最后出现盖楼奇观可能开辟了一个先河吧。这些不多扯,现在介绍一下如何在Django实现这种嵌套盖楼评论效果。Django在此只是负责提供model对象和表现,因此,这样的思路可以用于其他场合。
一般而言有这么几种方案: 1.当A用户引用B用户的评论时,直接将被引用的楼层(B)内容写入A的评论内容中。据说很多论坛程序是这么干的。Joomla的著名第三方插件jComments也是这么做的,样例在这里:http://verygif.com/recent/735-dog-pull-himself-out-.html 这个方案的弊端是由于前面累加的评论内容写到该用户的行里,所以他的发言数量受到影响、字数超出限制;并且当你需要删除或屏蔽某条,而它又被别人引用过,就成了很麻烦的一件事。 2.方案2是直接在数据表中放一个“引用目标”字段。用户评论有两种状态,要么是孤立未引用别人的,要么是引用了的。若A引用了B的发言,则将B的id写到A的这个字段里去。然后在显示时再去检索B的内容,如果B也引用了其他人的发言则继续检索、显示……其实这就是递归下去,直到遇见一个孤立的发言,中止,返回。 这个方案的弊端是:…需要理解递归 我这里使用的就是方案2,这里主要攻克的就是如何实现这个递归函数。次之的困难是如何将这一堆querySets 传递给Django 的Template系统,这个方面我就用略有悖于Django设计思想的办法,难看地实现了,这个自然是很有改进空间的,不过既然作为尝试,就不在这个方向深入。
【数据表的设计】:
id|author|quote_who|comment|created_time
【递归】:
设计1个函数comment_blocks,要求:
输入:某条评论的id
返回:1个字典。{1:querySet1, 2:querySet2,…}
该条评论的内容、该条评论引用的评论的内容、该条评论引用的评论引用的内容…..
def comment_blocks(qs_id, c_dict={}, sum=0):
c = Comments.objects.all()
if not c.filter(id=qs_id):
return c_dict
else:
qs = c.get(id=qs_id)
sum = sum + 1
c_dict[sum] = qs
if not qs.quote_who:
return c_dict
else:
qs_id = qs.quote_who
return comment_blocks(qs_id, c_dict, sum)
设计1个函数comment_blocks_html,
输入:1个字典。{1:querySet1, 2:querySet2,…}
返回:一个字符串。
'<div class="comment"><div class="comment"><div class="comment">...</div></div>'
def comment_blocks_html(c_dict):
if len(c_dict) == 0:
return u"no comment"
else:
n = len(c_dict)
head = u'<div class="comment">' * n
tail = u""
space = u" "*2
for i in c_dict:
j = n + 1 - i
tail = tail + unicode(c_dict[j].id) + space + unicode(c_dict[j].quote_who) + space + c_dict[j].author + \
space + unicode(c_dict[j].created_time) + u"<br />" + c_dict[j].comment + u"</div>"
result = head + tail
return result
然后在Views视图中迭代使用这两个函数,输出该页内容(所有评论)的html代码,直接通过context交给Templates。
def index(request):
c = Comments.objects.all().order_by('-id')
addcomform = Addcomform()
html_block = u""
for i in c:
qs_dict = comment_blocks(i.id, {}, 0)
qs_dict_html_block = comment_blocks_html(qs_dict)
html_block = html_block + qs_dict_html_block
context = {'c_list': c, 'addcomform': addcomform, 'html_block': html_block}
return render_to_response('index.html', context, context_instance=RequestContext(request))
以下为效果图,其中每条评论的第1个数字为自身id,第2个数字为目标(被引用者)的id。
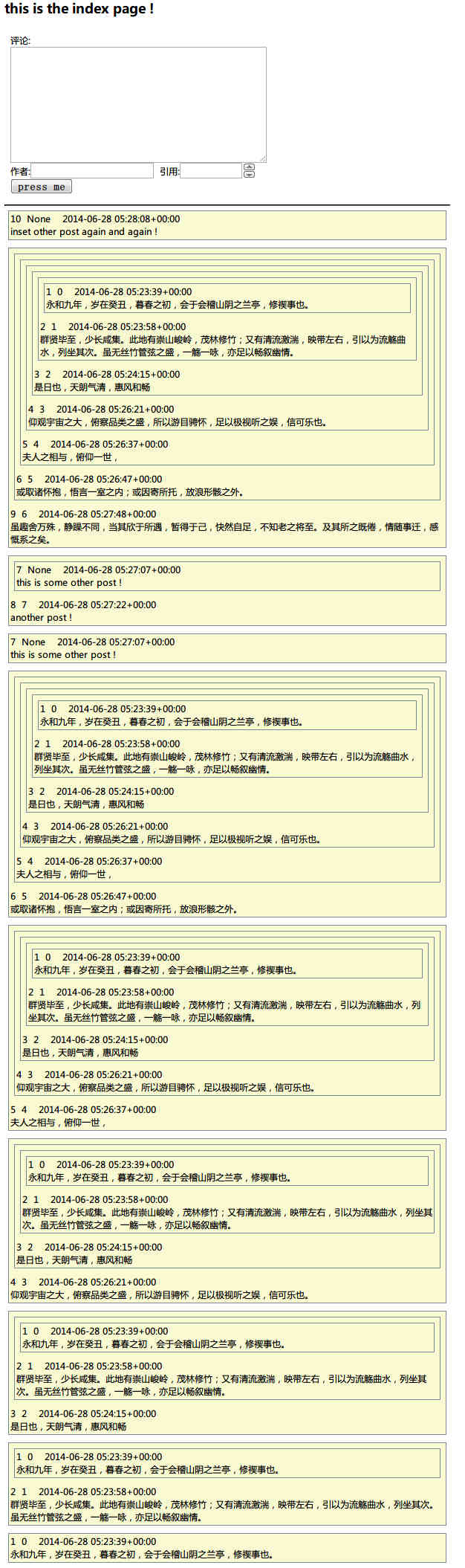
Django Template中 添加 list 的办法
2014-06-25 00:00假设有一个无context 变量传入的静态模版,
你需要加入一个自定义的list : [1, 2, 3, 4],
并随机取出里面的item,
可以使用这几行
{% with '1 2 3' as alist %}
{% for i in alist.split|random %}
<br /><img src="static/images/0{{ i }}.jpg" />
{% endfor %}
{% endwith %}
这里提供了一个在template tag 中 获取python语句结果的方法
https://djangosnippets.org/snippets/9/
ExprTag - Calculating python expression and saving the result to a variable
python 小程序:转换阿拉伯数字到拼音
2014-06-24 00:00python上提供转换汉字到拼音的包有很多,但是好像都没有针对阿拉伯数字转化到拼音的方法,
我这里写了一个,供有需要的朋友参考。
函数 digi_to_py
输入字符串: ‘上海1943’、’1024’、’1949大江大海’ …
得到字符串: ‘上海 yi jiu si san’、’yi ling er si’、’yi jiu si jiu 大江大海’ ….
import re
def digi_to_py(word):
digidict = {
'1': u'yi', '2': u'er', '3': u'san', '4': u'si', '5': u'wu',
'6': u'liu', '7': u'qi', '8': u'ba', '9': u'jiu', '0': u'ling'
}
patten = '([0-9]{1})'
for i in word:
if re.search(patten, i):
py = digidict[i]
word = word.replace(i, (u' ' + py + u' '))
return word
之后再使用其他汉字转拼音函数,即可得到不包含阿拉伯数字的完全的拼音字符串。
这样就避免了在按字母顺序排列的场合中,阿拉伯数字开头的item优先的情况。
具体实例:http://liyuwiki.com/577297.html
如不经过这一步转化 “1024”这样的词条就排到所有条目的前面去。
补充:
这个函数可以重写,直接用key匹配目标,,而不必使用正则表达式。
利用比特币中国提供的api自动进行比特币交易的脚本——一次不成功的编程
2014-02-23 00:00因为最近比特币大热,所以我也有进行过一点小额度投资,主要是在比特币中国这个场子内搞,央行出台不许充值的规定不久后比特币中国推出maker-taker机制,说辞是用以用户们抑制过度投机。
BtcChina的k线图显示有不少挂单是随着当前成交价格而实时、瞬间挂出的,这说明有人使用程序来挂单,也说明恰当利用这个机制能够获利。观察到这个现象,我便开始动了心思。
比特币中国提供了可以实现查询、交易、提现等动作的api,并有一点文档。再经过若干搜索之后,发现所需要的东西都够了,遂动手写了个交易脚本,循环执行。
主要思路是:
- 获取本账户所持现金、比特币余额、挂单情况;
- 获取当前最新成交价格
- 根据设定条件撤单、再自动以最新成交价格的±0.01元价格下买/卖单
最终达到不停买入卖出,不停成交,赚到手续费,而无论市场走低或走高。
对于这个实实在在涉及金钱操作的脚本,我思考得无比谨慎,大约花了3天之后,它可以说完美地实现了我的需求,不断去获取账户信息、进行买卖下单撤单;如果网络堵塞中断,它会发出警报以提醒。
然后遗憾的是,实践证明,从赚钱的角度来看这个思路一开始就是错的,脚本运行2天之后我看到它数十个挂单交易总是“高买低抛”,而所赚取的交易返利不足以弥补这个损失,最终的结果便是账户的现金或比特币逐渐轻微的减少。
那么,现在那些每秒钟都在挂单抛单的机器人们,它们背后是什么操作策略来确保获利呢?这是个值得探索的问题,如果找到答案,或许便可不必为斗米折腰、安心去做其他更有意义的事。
但从编程生涯来看,这个过程非常享受,激情,肾上腺素极大分泌,非常好的体验。
Sublime text 2 中,拼音输入法不跟随光标的解决办法:
2013-10-27 00:00其实这个问题困扰我很久了,导致sublime text 一直不能扶正成为主力编辑器的重要原因,今晚随手搜一下,一个台湾网友的post已经给出答案了,原来有个日本人写了个小插件: IMEsupport, windows only. 安装办法:在package control:install package中搜索这个名字即可。 原post 在: http://sublimetextlove.tumblr.com/post/41788388348/imesupport
插件在: https://github.com/chikatoike/IMESupport
用了3分钟即发现一个小bug,layout为2 column 时,另一个窗口如没有打开文件,仍可能导致候选词列表不跟随。
写了一个应用于工作中的小程序——使用sikuli 脚本进行百度搜索点击:
2013-10-27 00:00上周,根据boss指示,为了抑止生意上的竞争对手的购买我方关键词、恶意竞价、占据搜索结果前列的行为, 我拿了台老掉牙的笔记本,跑起一个sikuli脚本,试图大量点击对方竞价词,使对方账户消耗完当日费用提前下线。 这是个脏活,且尚处于试验阶段,本不宜细说。但作为一次极快速的编程实践,我在此粗略的记录一下。
工具:win7 + sikuli + Firefox + Chrome + 各种 addons
思路很简单:
隐身模式打开浏览器Firefox;
前往Baidu.com;
如网络不畅则或误打开m.baidu.com,则等待数秒重新打开,直至看到百度搜索按钮;
键入关键词1,搜索;
在结果页面中,查找匹配的若干个链接,逐个点击(把目标图片放在list里,随时添加新的,就可以一口气点多个了);
滚动浏览器搜索结果页至第二屏,继续寻找目标点击;
退出浏览器;
......
前往某个文件,做一次成功的记录;
前往本地路由管理页面,重启路由;
睡42秒;
以上,在range(99999)下反复的loop。各处条件及循环次数可适度修葺,则不至遗漏每一个广告。
基本思路就是这样,按此执行则大约每2分钟换一次ip,能给予竞争对手每小时被点击40-70的伤害值。
但由于做的判断和循环,尚不够完美,偶尔会因Firefox性能及网络响应问题,
陷入了不可预知的局面中而无法脱身:
比如Firefox突然启动过慢,或迟迟打不开页面找不到预定目标,
使得这个脚本中止。
也就是说无法完全的达到“无人值守”,有待优化或重构。
但这是一个很…..有意思的过程:
上手了一门新的语言sikuli(其实也就是python的亲戚啦);
用这门语言做事的人们的问答和帮助(居然不是在stackoverflow 最多);
了解到英国有一小群人为了逃避广告商的侵犯,
开发了一个牛逼哄哄的fx addons(可以随机切换浏览器发到服务器的所有header信息,不仅仅是 user agency哦);
也有几处比较疑惑的地方:百度竞价的判断机制,我的100个点击到底有多少生效?根据自己的少量测试,约1/3强的被计入了有效消费;如果用noScript 之类干掉百度的js,效果又会怎样呢?这些方面缺乏指导,也搜不出什么说法来。