使用python+Django 简单实现网易评论的无限嵌套 代码样例
一向觉得163网易评论,是国内文章评论系统做得最优秀的,除了本身运营的自由开放态度之外,技术上的因素也很重要:它的多层嵌套最后出现盖楼奇观可能开辟了一个先河吧。这些不多扯,现在介绍一下如何在Django实现这种嵌套盖楼评论效果。Django在此只是负责提供model对象和表现,因此,这样的思路可以用于其他场合。
一般而言有这么几种方案: 1.当A用户引用B用户的评论时,直接将被引用的楼层(B)内容写入A的评论内容中。据说很多论坛程序是这么干的。Joomla的著名第三方插件jComments也是这么做的,样例在这里:http://verygif.com/recent/735-dog-pull-himself-out-.html 这个方案的弊端是由于前面累加的评论内容写到该用户的行里,所以他的发言数量受到影响、字数超出限制;并且当你需要删除或屏蔽某条,而它又被别人引用过,就成了很麻烦的一件事。 2.方案2是直接在数据表中放一个“引用目标”字段。用户评论有两种状态,要么是孤立未引用别人的,要么是引用了的。若A引用了B的发言,则将B的id写到A的这个字段里去。然后在显示时再去检索B的内容,如果B也引用了其他人的发言则继续检索、显示……其实这就是递归下去,直到遇见一个孤立的发言,中止,返回。 这个方案的弊端是:…需要理解递归 我这里使用的就是方案2,这里主要攻克的就是如何实现这个递归函数。次之的困难是如何将这一堆querySets 传递给Django 的Template系统,这个方面我就用略有悖于Django设计思想的办法,难看地实现了,这个自然是很有改进空间的,不过既然作为尝试,就不在这个方向深入。
【数据表的设计】:
id|author|quote_who|comment|created_time
【递归】:
设计1个函数comment_blocks,要求:
输入:某条评论的id
返回:1个字典。{1:querySet1, 2:querySet2,…}
该条评论的内容、该条评论引用的评论的内容、该条评论引用的评论引用的内容…..
def comment_blocks(qs_id, c_dict={}, sum=0):
c = Comments.objects.all()
if not c.filter(id=qs_id):
return c_dict
else:
qs = c.get(id=qs_id)
sum = sum + 1
c_dict[sum] = qs
if not qs.quote_who:
return c_dict
else:
qs_id = qs.quote_who
return comment_blocks(qs_id, c_dict, sum)
设计1个函数comment_blocks_html,
输入:1个字典。{1:querySet1, 2:querySet2,…}
返回:一个字符串。
'<div class="comment"><div class="comment"><div class="comment">...</div></div>'
def comment_blocks_html(c_dict):
if len(c_dict) == 0:
return u"no comment"
else:
n = len(c_dict)
head = u'<div class="comment">' * n
tail = u""
space = u" "*2
for i in c_dict:
j = n + 1 - i
tail = tail + unicode(c_dict[j].id) + space + unicode(c_dict[j].quote_who) + space + c_dict[j].author + \
space + unicode(c_dict[j].created_time) + u"<br />" + c_dict[j].comment + u"</div>"
result = head + tail
return result
然后在Views视图中迭代使用这两个函数,输出该页内容(所有评论)的html代码,直接通过context交给Templates。
def index(request):
c = Comments.objects.all().order_by('-id')
addcomform = Addcomform()
html_block = u""
for i in c:
qs_dict = comment_blocks(i.id, {}, 0)
qs_dict_html_block = comment_blocks_html(qs_dict)
html_block = html_block + qs_dict_html_block
context = {'c_list': c, 'addcomform': addcomform, 'html_block': html_block}
return render_to_response('index.html', context, context_instance=RequestContext(request))
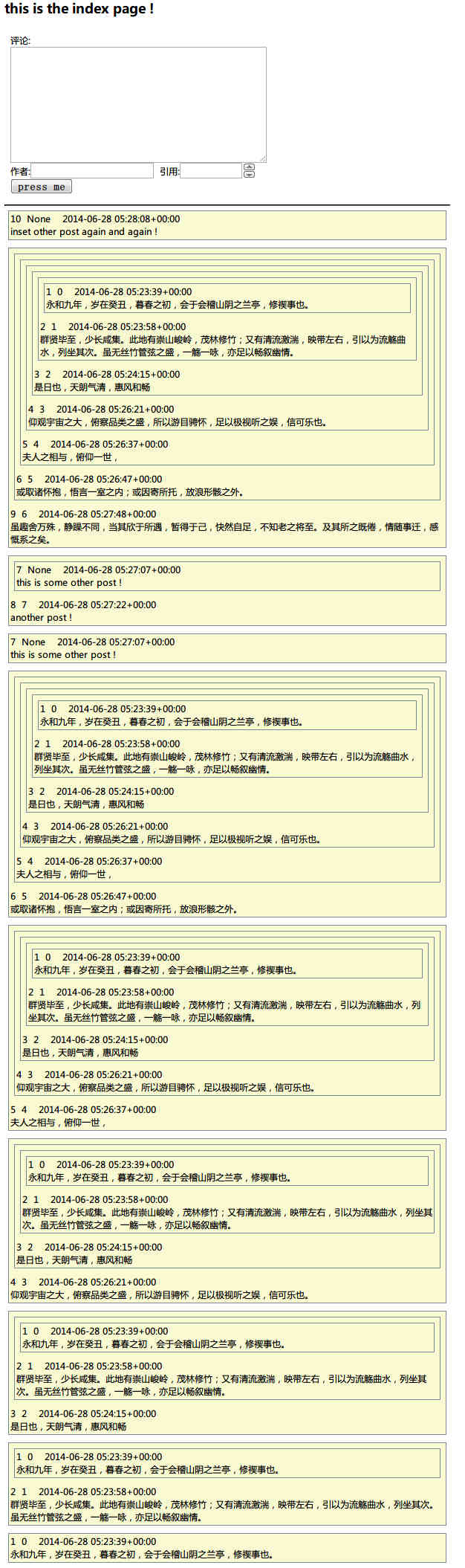
以下为效果图,其中每条评论的第1个数字为自身id,第2个数字为目标(被引用者)的id。